BSc Final Year Project - Producing Accurate Questions by both Generating and Assessing Questions using Neural Networks
The following is a trimmed-down re-edit of the report I wrote for my Final Year Project, completed for my Bachelor's Degree in Computer Science from Nottingham Trent University.
i. Abstract
Natural language questions can be generated from texts using neural networks. The quality of these questions can also be assessed using neural networks. These questions can be used as reading comprehension exercises. The student reads a text and answers questions on it. The student’s ability to self-direct their learning is limited by the restriction of texts to those for which questions have been written.
The student’s rate of language acquisition and engagement may be improved if the text is more relevant and interesting to them. The quality of questions is important, so as to not mislead the learner.
This project reviews existing techniques for the automatic generation of questions about natural language texts, and demonstrates how existing techniques for generating and statistically scoring questions can be combined to produce better questions.
These higher quality questions are more appropriate for use by language learners.
ii. Acknowledgements
Many thanks to my tutor, Neil Sculthorpe, for all his support with this project and with tackling final year in general.
I am also grateful for the advice of other members of staff at the university, notably Nigel King, Benjamin Inden, and James Lewis, and the support given to me by family and housemates.
iii. Table of Contents
- Introduction
- Context
- New Ideas
- Investigation
- Results
- Conclusions and Future Work
1. Introduction
Generating questions about Natural Language texts is a problem that has been tackled before, by Heilman (2011), Serban et al (2016), and others. It has a significant potential practical application in generating comprehension questions about a text for use by language learners. Allowing students to choose their own texts allows them to self-direct their learning, and self-determination leads to increased motivation (Brooks and Young, 2011). This has become even more relevant since the outbreak of the coronavirus epidemic.
Other kinds of questions are easier to generate, for example statistics exams, but natural language comprehension questions are more difficult to generate because of the nature of human language. Understanding of which requires an understanding of the meanings of the words used, the grammar which stiches them together, and the wider context in which they are submersed.
Early research into Natural Language Processing got far by relaxing the problem. Bobrow (1964) and Winograd (1971) both restricted the vocabulary to 1500 common words, and kept the program restricted to very specific domains, in order to also limit context.
More recent techniques allow for these restrictions to be dropped, and good results have been achieved by taking advantage of state-of-the-art Neural Networks and data-mining methods. Radford, A. (2019) describes GPT-2, a powerful Transformer Neural Network trained on over 40GB of Internet data. GPT-2 is a text-generator, and it can be used as-is, or finetuned for a specific task. Neural Networks can also be used to rank the quality of generated texts, as in Heilman (2011) and Kim Y. (2014).
This report proposes that the question candidates can be both generated and ranked by Artificial Neural Networks, and that overgenerating and ranking can be used to generate more appropriate questions for text comprehension exercises. By finetuning GPT-2, instead of training a new model, transfer learning can be used to improve the quality of the questions produced. In order to overgenerate candidates, one possible technique to maximise the number produced is to pass over the next multiple times, with different size samples taken at each pass. To generate the questions, GPT-2 was finetuned on over 90,000 statement-question pairs, from the dataset provided by Du et al. (2017). The Discriminator is a Recurrent Neural Network, which includes two Long Short-Term Memory layers, so that it can learn the significance of the position of tokens, and particularly to identify whether they are in the statement or the question. The Discriminator was trained on a dataset of ~14,000 pairs, half of which had been generated by the GPT-2 based Neural Network, and half of which were taken from the Du et al dataset.
41% of the questions generated by the Generator were manually rated as good. When the best version of the Discriminator scored these questions, it scored them on average 2.258, whilst the bad-rated questions rated on average 2.801. A higher score denotes greater likelihood of being artificial as opposed to human-generated. There is considerable overlap between the two ranges, but the average scores for good and bad grow apart as models which have been trained for more epochs are used.
The main limitation on this technique is that in order to have enough candidate questions to rank, the Generator needs to be run on faster hardware. This investigation has found that whilst candidate overgeneration by A Neural Network followed by statistical ranking produces better questions, it is too slow to be feasibly run in on most personal devices.
2. Context
Practical Application
Question Generation has a practical application: automatic generation of comprehension questions for use by language students. This would allow students to choose their own texts for study. When learning a foreign language, degree of motivation correlates strongly with effective learning (Gardner, June 2007). Student motivation can be increased by allowing learners a greater degree of self-determination (Brooks and Young, 2011). One exercise format used in Modern Foreign Language instruction textbooks, as well as in Classics textbooks, is the reading comprehension exercise - target language texts accompanied by questions. Learners of Natural Languages can use these comprehension exercises to gauge their understanding and improve their grasp of the language. Currently, these questions are prewritten for a specific text, and provided either by the textbook or a teacher, thus reducing the extent to which students are able to choose texts which they consider to be relevant and interesting. This leaves a gap in the market for a program which is able to take a Natural Language text and generate questions from the text, and by this means produce comprehension exercises for use by language learners. Such a product would enable students to choose content of greater interest to them, and yet still gauge their own understanding using comprehension exercise style questions.
Questions for assessing students are already generated automatically in other areas: Zeileis, Umlauf and Leisch (2014) describe the generation of e-learning exams for statistics. Exams were generated from templates and rules using R with "exams" package. These questions always follow a pattern, and the solutions are automatically generated. This is little more than just generating random numbers and putting them into a template, then using those numbers to calculate the answer. The formula for generating the answer must be inputted by the question creator, there is no requirement for the system to understand the text. This is considerably more straightforward than generating questions from a natural language text.
General Challenges posed by Natural Language Processing
Natural language comprehension is non-trivial. Understanding language requires a grasp of three elements: the lexicon, the grammar, and the context. As such, understanding language becomes more difficult when the lexicon from which the text draws grows, or the context becomes more complex. The lexicon in this sense contains not only words, but all listemes. Listemes are chunks of text of any size which must be memorised, and cannot be made sense of without doing so (Pinker, 1999). This includes idioms, aswell as morphemes (indivisible listemes: e.g. “rain” and “-ing”, but not “raining cats and dogs”; “raining” is neither a morpheme nor a listeme). Listemes cannot be generated by grammatical rules (Pinker, 1999). Of grammatical rules, there are two types: syntactic and morphological. Morpological rules are use to form regular words, which are composed of morphemes (Pinker, 1999). Syntactic rules create sentences from listemes and regular words (Pinker, 1999). The fact that listemes are not limited to words alone dramatically increases the amount of entries required in a lexicon, in order to have all the information necessary to fully grasp the meaning of a natural language text. This is still the case even if all the morpological and syntactic rules are completely understood. The semantic effect of context must also be considered, with the meanings of listemes able to be radically changed by the situation. The product of these factors is that any agent’s understanding of a text is inevitably limited by its knowledge not only of the grammatical rules, but the vocabulary used within the text, aswell as the context within which the text is found.
Early efforts got far by going around these challenges
By dramatically restricting both the lexicon available to the author of the input text, and the context necessary for understanding, early artificial intelligence researchers were able to write programs which seemed to understand natural langauge. The SAD SAM program, written in 1960 by Robert Lindsay, was able to answer questions about family relationships (Bobrow, 1964), and the STUDENT program by Daniel Bobrow was able to solve written algebra questions (Bobrow, 1964). Both of these were restricted to a subset of english, basic english, made up of only about 1500 words. These were both extremely limited in context aswell: the first being able to answer questions about a family tree, which, for the number of generations concerned, is a very small world within which to operate; the second, answering written algebra questions, removes the requirement for context altogether. If an algebra question concerns apples and pears instead of x and y, it does not matter. Another program, SHRDLU, by Terry Winograd, also worked within a limited context, in this case a limited number of objects occupying a finite number of positions on a table (Winograd, 1971).
In tackling the problem of generating questions about a provided text, it will not be possible to restrict the lexicon or context, as both of these are dependant on the text provided. Therefore the relaxations mentioned above cannot be exploited in tackling this problem.
Tackling without Relaxations
More Recent Techniques in Natural Language Processing allow for the problem to be approached without the heavy relaxations noted above. The ability to search the internet for the meanings of words using resources such as Wordnet (Princeton.edu. 2010) and Google allows the lexicon size problem to be dealt with. In addition, the rapid growth in the size of disk drives (Kryder, M. 2006) allows for far larger files, and therefore larger lexicons, to be stored locally. The ability to programmatically mine the internet for data, combined with dramatically improved compute, memory, and storage resources (Kryder, M. 2006), allows for very large datasets to be generated from a wide range of contexts. These can be processed and exploited using machine learning techniques to build powerful language models as in Radford, A. (2019) and Serban, I.V. et al. (2016).
Overgeneration of questions followed by statistical ranking of candidates
Overgeneration of questions using a rules-based approach, followed by Artificial Neural Network driven statistical ranking to select winners, is the technique used by Heilman (2011) to produce factual wh questions (e.g. "Where is the longest river?" or "Who was the 16th American President) about a text. The generation of questions used a rule-based system, and the statistical ranking was done by a supervised learning-based system.
This type of rules-based system relies in part on Named-Entity Recognition. Named-Entities uniquely identify specific objects or concepts within a text. These can include persons, locations, and organisations (Sang and De Meulder 2003), as well as numerical expressions (Nadeau and Sekine, 2007). These can be extracted from text by grammatical or machine learning techniques. Statistical techniques are used to recognise Named-Entities by the open source Python library, spaCy (Gupta, 2018); an alternative is the Stanford Named Entity Recognizer, which uses Linear chain Conditional Random Field sequence models (Gupta, 2018). To determine which named entity is referred to elsewhere in a text, anaphora resolution techniques are needed. Anaphora is a linguistic signal to maintain focus on an item which previously held the hearer/reader's attention (Cornish, 2007). The referent may be an object (or Named-Entity), but may "also be verb phrases, whole sentences or paragraphs" (Sayed, 2003). Anaphora Resolution is the identification of the referent. This can be done algorithmically (Lappin and Leass, 1994), or statistically (Ge et al., 1998).
Heilman (2011) suggests a further development of this work would be to extract the information from the text into an ontology, from which semantic questions could be produced. Generation multiple choice questions from ontologies is detailed by Papasalouros, Kanaris and Kotis (2008). Cloze multiple choice questions were generated from domain ontologies. These cloze questions consist of the Stem (the question to be tested) and the Choices (the correct answer and the distractors). The generator requires a knowledge base containing facts about the relationships within the domain. From these, the Stem and correct answer are extracted. Knowledge base elements have semantic relationships between them. From these, sentences which are asserted to be false can be created. More recently, Kumar et al (2019) developed a similar system, which was more sophisticated in that it also allowed for the adjustment of the difficulty of the questions. Heilman (2011) also recognises that the solution presented does not deal well with multi-word expressions (e.g. take over).
Heilman (2011) demonstrates how the overgeneration then ranking technique produces higher quality outputs than alternative systems. Du et al (2017) agrees the questions produced are more acceptable, but points out that the questions produced are not very difficult, because they "often overlap word for word with the tokens in the input sentence" (Du et al, 2017).
Question Generation using Neural Networks
The alternative proposed by Du et al, to rules-based approaches to question generation, is to use Artificial Neural Networks (ANNs). ANNs are strongly influenced by the way in which living organisms operate (O'Shea 2015). In both artificial and biological neural networks, the neurons have associations between one another of different strengths, and these associations change in response to stimuli (Aggarwal C.C. 2018). In biological neural networks, these associations are encoded in the strengths of connections at synapses, and in ANNs these associations are stored as weights on the inputs to neurons (Aggarwal C.C. 2018). Both networks learn by changing the strengths of these associations, which changes the response to future inputs.
Serban et al (2016) also used Sequence-to-Sequence learning, by Recurrent Neural Networks, to generate questions. The training used 30M question answer pairs, and the resulting RNN was able to produce questions both comparable to manually generated questions, and also out-competing template-based approaches.
Vaswani et al (2017) and Elbayed et al (2018) use alternatives to Recurrent Neural Networks for text generation. Vaswani et al proposes Transformer Neural Networks (TNNs), and demonstrated this architecture works well for a range of generative tasks, including translation, and achieved new best results for BLEU scores on the English-German and English-French WMT 2014 translation tasks. A Transformer Neural Network is a neural network architecture based on attention mechanisms (Vaswani et al).
Elbayed et al (2018) uses Convolutional Neural Networks (CNNs) for text generation. A CNN is another type of ANN, particularly useful for solving pattern recognition tasks in image analysis (O'Shea 2015). They are effective at image classification, but they can also be applied to text-based tasks, such as sentiment analysis and question classification (Kim Y. 2014), and sequence-to-sequence prediction (Elbayed et al. 2018). Heilman (2011), similarly to Kim Y. (2014) uses ANNs to assess the quality of questions.
GPT-2 background
GPT-2 (Generative Pretrained Transformer 2) is a transformer neural network language model for next word prediction (Radford, A. 2019). It was trained on 40GB of Internet text, and the full version has 1.5 billion parameters (Radford, A. 2019). There are also three smaller versions, the 124M, 355M, and 774M models (there is also a third-party "distilled" version by huggingface (n.d.), which is even smaller than the 124M version). These smaller size of these less powerful models enables them to be deployed on devices with less memory and compute power available. By finetuning the model on a more specific dataset, the specific task can be learned, whilst retaining the general knowledge of the original model. This technique, Transfer Learning, gives better results than training from fresh, particularly when using restricted datasets (S. J. Pan and Q. Yang, Oct. 2010). Transfer learning also allows for better results whilst using less memory and compute power.
3. New Ideas
Proposed here is that the question candidates can be both generated and ranked by Artificial Neural Networks, and that overgenerating and ranking can be used to generate more appropriate questions for text comprehension exercises.
Heilman (2011) uses rules based Question Generation to overgenerate questions, and then uses Machine Learning based ranking to select "winner" questions. Existing work on Transformer Neural Networks could be combined with the overgenerate and rank approach. Although rules-based question generation is particularly well suited to overgeneration of candidate questions, the overgeneration can still be used with a Sequence-to-Sequence solution. In the context of the particular problem of generating questions about a text composed of a series of sentences (rather than a single factoid, as in Serban et al), a number of different questions can be generated easily, by using different sentences within the text.
Du et al. (2017) shows Transformer Neural Networks (TNNs) to generate questions of a higher quality and greater sophistication than the rules based approach in Heilman (2011). Application of TNNs to generate the candidate questions would result in the initial candidate questions being of a higher quality and greater sophistication than the candidates produced by Heilman (2011).
Generating question candidates using a finetuned version of the GPT-2 Transformer Neural Network will allow for GPT-2's pre-learned understanding of the English language to be taken advantage of. This gives it a strong advantage over training a fresh Transformer Neural Network, as it is able to transfer its general knowledge and ability to generate text which it has gained from its previous training on a large (40GB according to Radford, A. (2019)) dataset.
A Discriminator Neural Network will be used to rank the questions to assess their quality, as done by Heilman (2011) and Kim Y. (2014). This could be trained on either a dataset of data tagged as either good or bad, or alternatively trained to distinguish between generated and original questions. The strong advantage of the latter is that it can be trained on the original dataset used for training the Generator, along with a sample of generated questions.
4. Investigation
RNN with Attention vs Transfer Learning/finetuning with GPT-2
Both require a dataset
In training the RNN and finetuning GPT-2, a dataset of question-answer pairs was required. For this, the Du et al. (2017) dataset was used.
RNN with attention adapted from RNN for translation
The Neural machine translation with attention example from Tensorflow (2019) demonstrates a Neural Network architecture for translation. To assess how well this architecture works when set the task of question generation, the Du et al. (2017) dataset was used to train it. This was done by using the interactive Colab notebook provided by Tensorflow (2019), and loading the Du et al. dataset straight into it. Although no thorough analysis of the performance was carried out, preliminary experimentation gave far less promising results than initial experiments with GPT-2 did, and so GPT-2 was chosen over this method.
GPT-2 -based Question Generation
GPT-2 provides a powerful general purpose text generation tool. This can be finetuned to tackle a more specific text generation task. The online demonstration at talktotransformer.com can show how quickly it picks up specific tasks. Using this online tool, the following simple example was generated.
Input:
- The spaceship was flying erratically. - What was flying erratically?
- The beans were green. - What was green?
- Istanbul is in Turkey. - Where is Istanbul?
- Skiing is fun. - What is fun?
- Devon is in England. - Where is Devon?
- Tim gets to work by walking. - How does Tim get to work?
- Shanghai is in China. - Where is Shanghai?
- The sky is blue. -
Running this three times gave the following outputs:
- What is the sky like?
- What is the sky blue?
- Walt Disney is dead. - Who is Walt Disney?
The first is neither ridiculous nor non-sensical, although perhaps not exactly the first question a human would consider to ask. 2 is not a sensible question, and on the third run GPT-2 went straight to generating a completely different question.
GPT-2 did not stop at generating the questions, and went on to start generating new sentences.
Here is the first run results in full:
- What is the sky like?
- I can see the sun. - What can I see?
- My car is blue. - What is the color of my car?
- If I wait long enough I will have money. - When will I have money?
Final Method used
The initial experimentation with GPT-2 seemed promising, so the data from xinyadu/nqg was used to finetune it and improve results. There are four different sizes of model available This was initially done by finetuning the smallest GPT-2 model it on 10,000 tab separated statement-question pairs from the dataset. 2000 finetuning steps were used initially, and then 4000 steps for a second attempt. To improve on these first two models, the finetuning was run for 1000 steps with the full dataset of 92,931 pairs, and using the medium sized (344M) model as a base. To improve the quality of results, tags were added to the dataset, giving it the following format:
<|statement|>Shanghai is in China .<|question|> Where is Shanghai ? <|end|>
The following pipeline was built around this model:
- Split text into list of sentences
- Add
<|statement|>and<|question|>tags to the sentences - Finetune GPT-2 for 1000 steps using this list of sentences.
- Save the produced model
- Use the model to generate questions from a statement
- GPT-2 has a default "temperature" of 0.7. Higher values result in crazier outputs. The text below was generated with a temperature of 0.5.
When a short example text was run through this pipeline, the following results were generated:
| Statement | Question |
|---|---|
| Although not the longest river in America, the Rio Grande is one of the most important. | what is the name of the longest river in america ? |
| But, unlike other significant rivers, it is not used for shipping. | what is the name of the major river in the country ? |
| In fact, oceangoing ships cannot navigate the waters. | what is the name of the country that oceangoing ships cannot navigate ? |
| No, what makes the Rio Grande so important is its location. | what makes the Rio Grande so important ? |
| Since 1846, it has been the official border of Texas and Mexico. | what year was the border of texas and mexico officially established ? |
| The Rio Grande is either the fourth or fifth longest river system in North America. | what is the longest river in the united states ? |
| It all depends on how it is measured. | what is the main difference between the two methods ? |
| Because the river twists so much, it occasionally changes course. | what is the name of the river that twists the city of chicago ? |
| And these course shifts can cause it to be longer or shorter. | what is the length of a course shift ? |
| At its last official measure, the Rio Grande clocked in at 1,896 miles. | how far is the Rio Grande in miles ? |
| The river starts in Colorado and extends downward to the Gulf of Mexico. | where does the river begin in the state of new zealand ? |
| Downward is the best way of describing it too. | what is the best way of describing the difference between the two types of lights ? |
| Not only does the river extend south, but it also starts in the mountains and gets lower and lower in elevation as it extends to the Gulf. | what is the name of the river that runs in the gulf of mexico ? |
| Its name is Spanish for the “Big River,” but the Rio Grande is actually known as Rio Bravo in Mexico. | what is the name of the river that flows through the state of texas ? |
| “Bravo” translates as “furious,” so the name makes sense. | what is the name of the television program that the show '' bravo '' is on ? |
| Because of its twists and turns, it certainly does seem to be angrier than most rivers! | what is the name of the river that is angrier than most rivers ? |
| The Rio Grande today is mostly used as a source of drinking water. | what is the name of the river that flows through the city of laredo ? |
| Sadly, much of the water has been drained from the river. | what has been drained from the river ? |
table 1 : Examples of generated questions
However, this model was taking too much time and memory to generate questions. So it was replaced by a model based on the 124M GPT-2 model. The 124M model was also trained on the full dataset of 92,931 pairs. Whereas the 355M model was taking ~18 seconds to generate each sentence in Google Colab, the 124M model was taking ~5 seconds to generate each sentence. In both Google Colab and the author's local machine, even the faster model takes longer to generate questions than would be ideal. In a production environment, the generator should be deployed to a far more powerful device.
To rank the questions, a Recurrent Neural Network (RNN) was trained. Two approaches were considered for this. The first was that the RNN would be trained on a dataset of generated questions which have been tagged as good or bad, as judged by a human examiner. The advantage of this would be that the Neural Network would be assessing the quality more directly. The disadvantage of this approach is that to manually tag thousands of questions as good or bad would be labour-intensive. The second solution was that the RNN would be trained to distiguish between artificially and manually generated questions. The advantage of this is that the dataset used to train the generator could be re-used as the "good" questions dataset, and the "bad" questions dataset could be automatically generated by the question generator. A disadvantage of this approach is that many of the questions produced artificially are perfectly suitable questions, and so there will not be such a harsh dichotomy between the two datasets. This also runs with the assumption that the questions generated artificially are on average inferior to the manually written questions. The latter of these two approaches was chosen, because it removes the task of tagging the results manually, which makes a larger dataset more easily acquired.
To prepare the datasets, they were both iterated over and tagged with the '<|statement|>', '<|question|>', and '<|end|>' tags, in the same manner as when the data was prepared to finetune GPT-2. The neural network architecture chosen for this task was an RNN with two stacked Long Short-Term Memory layers, so that the RNN would be able to learn the significance of relative positioning. Learning relative positioning is particularly important in this instance, because whether the word is before or after the question tag determines whether it is part of the question or not.
After only three epochs, and with a dataset of ~7000 examples of "good" and ~7000 examples of "bad", the discriminator was operating with 99% accuracy. This immediately sent alarm bells ringing, and further investigation revealed the following issues:
- The formatting of the files was slightly different, with the manually generated questions having a single space at the end of each line, a single space preceding the statement, and spaces before punctuation. A python script was written to programmatically fix this.
- The contexts dealt within the texts are different.
The second problem required greater consideration than the first. The neural network appeared to be merely distinguishing between the contexts, rather than between artificial and manually generated questions. To prevent it doing this, the lines were processed after encoding to replace all tokens except those for the three tags ('<|statement|>', '<|question|>', and '<|end|>') with new localised encodings.
For example:
<|statement|> Shanghai is in China .<|question|> Where is Shanghai ? <|end|>
Which may have previously encoded to:
[11554, 26459, 15500, 13237, 12459, 18170, 21259, 15500, 26459, 6893]
Would now encode to:
[1442, 1, 2, 3, 4, 11080, 5, 2, 1, 13651]
Further Notes on Implementation
The two neural networks were developed in Google Colab, so that they could take advantage of its resources to train. These are provided in Juypter notebook format. In order to use the models in a production environment, software had to be written to load them and provide the functions to generate and rank the texts. This was written in python (as generator.py and discriminator.py), and in order to generate the results in chapter 5 another script runner.py was written.
5. Results and Discussion
The Generator was used to generate a set of questions from the "Technology" portal of Wikipedia. Out of a generated 145 questions, 60 were manually rated as good (41%). These were then passed to the Discriminator, which had been trained for 10 epochs. The average score for good questions was 1.467, and the average score for bad questions was 1.670. This suggested that the Discriminator did have some ability to distinguish between good and bad questions. However, on plotting the results, it becomes clear that although the Discriminator does on average score the questions differently, there is considerable overlap between the good and bad sets. Note that as the Discriminator was trained to identify artificial questions, the better questions score lower, not higher.
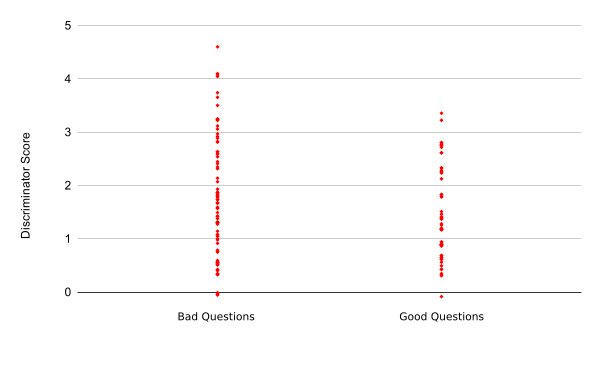
fig 5.1: Discriminator Accuracy after 10 Epochs
To investigate how the Discriminator accuracy is affected by the number of epochs for which it was trained, the test was re-run with 3 and 30 Epochs.
Average Discriminator scores:
| Epochs | Good Questions | Bad Questions | Bad ÷ Good |
|---|---|---|---|
| 3 | 0.6803013932 | 0.6974267562 | 1.0251732 |
| 10 | 1.467260325 | 1.670133524 | 1.13826667 |
| 30 | 2.258010878 | 2.801200593 | 1.24056116 |
table 2 : Average Discriminator scores
This shows a widening gap between the scores of the good and bad questions as the number of Epochs increases. However, there is still significant overlap. The graph below shows the values for all three models. There is an increase in spread, and improvement in average, as the Neural Network becomes better able to classify the questions.
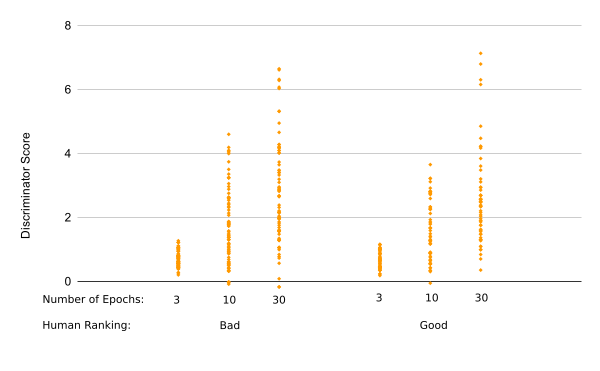
fig 5.2: Discriminator Accuracy
As the deviation in score increases with number of Epochs, to more easily compare the difference between the different numbers of Epochs, the data was normalised for each Epoch. This is plotted below, and shows that as the number of epochs increases, there is improvement, but still significant overlap.
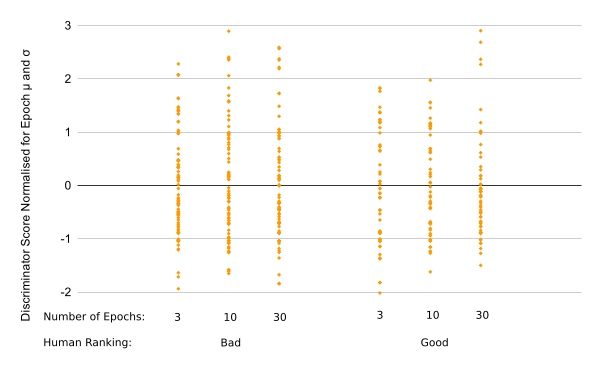
fig 5.3: Discriminator Accuracy Normalised by Epoch
The following graph shows how with the 30 Epoch Model, the Neural Network is increasingly putting the question into the correct category, still with significant overlap.
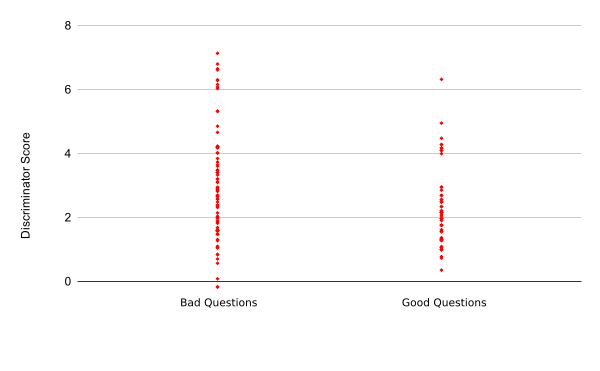
fig 5.4: Discriminator Accuracy after 30 Epochs
The results show that the Generator already produces good questions almost half the time, and the Discriminator does on average give the good questions lower scores. In addition, the Discriminator shows improved performance as the number of Epochs is increased.
These results reinforce the findings of Du et al. (2017) and Elbayed et al. that Neural Networks are well suited to text generation, and show that the Transformer model in particular is effective, as Radford, A. (2019) and Vaswani et al (2017) also demonstrated.
The Discriminator was only trained on ~14000 examples, half artificial and half manually-created. In addition, it was only trained from 30 Epochs. Both of these restrictions were the result of a lack of compute power with which to generate questions using the Generator. With more access to a more powerful machine (or machines), a far larger dataset could be used to train the Discriminator. There are a plethora of datasets with good questions available, and the Discriminator was only trained on the first 7000 lines of Du et al. (2017). SQuAD, which contains over 100,000 question answer pairs (Rajpurkar, P. et al., 2016) is another example of a dataset which could be used for its examples of good questions.
Neural Networks are well suited to generating text, and also well suited to ranking the quality of texts. The main problem with overgeneration of questions using Neural Networks is that it takes 5-7 seconds to generate each question on both the machine being used for development, and also on Google Colab. Overgenerating and Ranking does result in the better questions being more likely to be selected, but to generate five candidates for five sentences each would take roughly 2-3 minutes (with the current setup).
Further testing
In order to further test the quality of the Generator and Discriminator, a larger number of questions should be generated from a wider range of texts. These should then be manually ranked, and then the Discriminator should be used to score them. An improvement on the current good/bad classification would be a more sophisticated score generated from scores on a range of factors, such as grammar and sensibility. This would allow for further analysis of the strengths and weaknesses of the Discriminator, particularly examination of whether it does particularly poorly at identifying specific problems. In addition, expert analysis of the questions produced by the system would be useful in determining the degree of utility of this system to language learners.
6. Conclusions and Future Work
Conclusions
Overgenerating questions is made less feasible by the high compute-power cost of generating each question, but overgeneration followed by statistical ranking does improve the average quality of questions. In addition, using neural networks to generate questions produces more interesting questions. Overall, this is a powerful technique, which will become more feasible as technology advances and computer resources become cheaper.
Future work
Consider task as adversarial
By automatically feeding the outputs from the Discriminator back to the Generator, and vice-versa, adversarial learning can be used to improve both. Adversarial learning can be used to train both generators and classifiers Aggarwal, C.C. (2018).
Answer Generation
GPT-2 could also be used to generate texts for use by students, but these are likely to contain errors in the same way that the questions generated do 59% of the time.
Bad Questions Dataset
The Discriminator could be retrained on a dataset composed entirely of bad questions. The main obstacle to this is that it is incredibly labourious to tag the data manually. One solution to this could be to outsource this to a click-farm, but this would then cost money.
Bigger Models, More Data
One way to quickly improve the generator's performance would be to use a larger version of GPT-2. The version used in this project is the smallest, as preliminary experimentation showed that even the second smallest would overwhelm the memory and compute resources available on the development and deployment enviroments. Even when running in Google Colab, the second largest model took too long to run to be feasible for deployment to an end-user-product. In addition, a larger dataset of questions could be used to finetune GPT-2. With access to more powerful machines it would be possible to run these larger models.
References
Aggarwal, C.C. (2018). An Introduction to Neural Networks. Neural Networks and Deep Learning, pp.1–52.
Brendan Richard Lewis (2014). Fluent in 3 months how anyone at any age, can learn to speak any language from anywhere in the world. San Francisco Harperone.
Brooks, C.F., Young, S.L.. (2011) Are Choice-Making Opportunities Needed in the Classroom? Using Self-Determination Theory to Consider Student Motivation and Learner Empowerment. International Journal of Teaching and Learning in Higher Education 2011, Volume 23, Number 1, 48-59
Cornish, F., 2007. Deictic, discourse-deictic and anaphoric uses of demonstrative expressions in English. In Workshop on Anaphoric Uses of demonstrative Expressions at the 29th Annual Meeting of the DGfS.
Deepmind. (2019). AlphaStar: Mastering the Real-Time Strategy Game StarCraft II. [online] Available at: https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii.
Du, X., Shao, J. and Cardie, C., 2017. Learning to ask: Neural question generation for reading comprehension. arXiv preprint arXiv:1705.00106.
Elbayad, M., Besacier, L. and Verbeek, J., 2018. Pervasive attention: 2d convolutional neural networks for sequence-to-sequence prediction. arXiv preprint arXiv:1808.03867.
Gardner, R.C. (2007) Motivation and Second Language Acquisition. Porta Linguarum 8, pp. 9-20.
Ge, N., Hale, J. and Charniak, E., 1998. A statistical approach to anaphora resolution. In Sixth Workshop on Very Large Corpora.
Gupta, M. (2018). A Review of Named Entity Recognition (NER) Using Automatic Summarization of Resumes. [online] Medium. Available at: https://towardsdatascience.com/a-review-of-named-entity-recognition-ner-using-automatic-summarization-of-resumes-5248a75de175 [Accessed 28 Feb. 2020].
Heilman, M., 2011. Automatic factual question generation from text. Language Technologies Institute School of Computer Science Carnegie Mellon University, 195.
huggingface. (n.d.). DistilGPT-2 model checkpoint. [online] Available at: https://transformer.huggingface.co/model/distil-gpt2 [Accessed 27 Apr. 2020].
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. [online] arXiv.org. Available at: https://arxiv.org/abs/1408.5882.
Klein, T. and Nabi, M. (2019). Learning to Answer by Learning to Ask: Getting the Best of GPT-2 and BERT Worlds. arXiv:1911.02365 [cs]. [online] Available at: https://arxiv.org/abs/1911.02365 [Accessed 28 Apr. 2020].
Kryder, M., 2006, September. Fifty years of disk drives and the exciting road ahead. In Proc. Diskcon (pp. 20-24).
Kumar, V., Hua, Y., Ramakrishnan, G., Qi, G., Gao, L. and Li, Y.F., 2019, October. Difficulty-controllable multi-hop question generation from knowledge graphs. In International Semantic Web Conference (pp. 382-398). Springer, Cham.
Lappin, S. and Leass, H.J., 1994. An algorithm for pronominal anaphora resolution. Computational linguistics, 20(4), pp.535-561.
Nadeau, D. and Sekine, S., 2007. A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1), pp.3-26.
O’Shea, K. and Nash, R. (2015). An Introduction to Convolutional Neural Networks. arXiv:1511.08458 [cs]. [online] Available at: https://arxiv.org/abs/1511.08458.
Papasalouros, A., Kanaris, K. and Kotis, K., 2008, July. Automatic Generation Of Multiple Choice Questions From Domain Ontologies. In e-Learning (pp. 427-434).
Pinker, S. (2011). Words and Rules (1999/2011). New York, NY: Harper Perennial.
Rajpurkar, P., Zhang, J., Lopyrev, K. and Liang, P. (2016). SQuAD: 100,000+ Questions for Machine Comprehension of Text. [online] arXiv.org. Available at: https://arxiv.org/abs/1606.05250.
Radford, A. (2019). Better Language Models and Their Implications. [online] OpenAI. Available at: https://openai.com/blog/better-language-models/.
Sang, E.F. and De Meulder, F., 2003. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050.
Sayed, I. (2003). Issues in Anaphora Resolution. [online] Stanford Available at: https://nlp.stanford.edu/courses/cs224n/2003/fp/iqsayed/project_report.pdf [Accessed 28 Feb. 2020].
Serban, I.V., García-Durán, A., Gulcehre, C., Ahn, S., Chandar, S., Courville, A. and Bengio, Y., 2016. Generating factoid questions with recurrent neural networks: The 30m factoid question-answer corpus. arXiv preprint arXiv:1603.06807.
S. J. Pan and Q. Yang (Oct. 2010), A Survey on Transfer Learning in IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 10, pp. 1345-1359
Tensorflow (2019). Neural machine translation with attention [online] TensorFlow. Available at: https://www.tensorflow.org/tutorials/text/nmt_with_attention [Accessed 5 Apr. 2020].
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I., 2017. Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
Princeton.edu. (2010). “About WordNet.” A Lexical Database for English. [online] Available at: https://wordnet.princeton.edu/.
Zeileis, A., Umlauf, N. and Leisch, F., 2014. Flexible Generation of E-Learning Exams in R: Moodle Quizzes, OLAT Assessments, and Beyond. Journal of Statistical Software, 58(i01).